
Technology
SSIS 816: Advanced Features & Best Practices

SQL Server Integration Services comes as a valuable toolkit for data integration and business process management. Among various components of SSIS, SSIS 816 is an important component that helps to improve the performance and productivity of data processing. Discover SSIS 816’s advanced features, security, and best practices to optimize your data integration and workflows efficiently.
What is SSIS 816?
SSIS 816 relates to a package of functions in SQL Server Integration Services that are aimed at enhancing data management, and automation of workflows. Some of its characteristic features include improved data transformation, strengthened error providing and strong compatibility with other efficient aspects of SQL Server.
Key Features of SSIS 816
Advanced Data Transformation:
SSIS 816 represents the advanced related transformation additional to allow performing intricate data operations. This includes pivoting, unpivoting, and data cleansing operations that are essential for maintaining data integrity and accuracy.
Improved Error Handling:
In SSIS 816, handling of errors is enhanced compared to previous versions of the program. It enables precise error identification and tracking that progressively log errors and provide personalized error messages for continuous, uninterrupted data processing.
Seamless Integration:
Integration of the SSIS 816 with other aspects of SQL server was consistent, since it is one of the key strengths of this system. This is also evident through performing operations between databases such as joining, copying, and pasting between databases; integrating with SSRS as well as SSAS.
Scalability and Performance:
As Larger datasets are processed in SSIS 816 they are optimally processed so that there are minimal compromises. It manages the data flow and resources thus enabling your data operations to have a fast and ever expanding capacity.
Advanced Security Features in SSIS 816
Security for the data is one of the most important aspects that should be taken into consideration when working on the system. This course is very advanced and offers the following security features to support data integrity and privacy:
- Data Encryption: SSIS 816 has the capability of data encryption to ensure that any sensitive data does not fall into wrong hands during transference as well as storage. And by utilizing the standard encryption methods and algorithms preferred in the field of computer science, it aids in protection from intrusions.
- Role-Based Access Control (RBAC): This feature enables the administrators to grant usages access based on provided roles within the feature. It makes it possible to prevent misuse or amendment of information by unapproved staff members.
- Package Protection Levels: SSIS 816 has provided different package protection levels that include Encrypt Sensitive With Password and Encrypt All With User Key, through which users can safeguard reputable data in SSIS packages.
- Integrated Windows Authentication: SSIS 816 includes integrated Windows authentication that allows using the existing Windows security model for user authorization.
- Audit Logging: Audit logging in SSIS 816 helps in tracking of data changes and access by keeping a log of all the actions taken and performed on the same.
Common Problems and Solutions in SSIS 816
Users may face several possible issues when performing the workflow. Here are some issues and their solutions:
- Performance Issues: This means improving the capacity of effective data flow tasks in relation to resources provided for task accomplishment. Use techniques such as performance tuning, optimize the use of buffer size and the parallel execution of packages.
- Data Loss During Transfer: Utilize the appropriate quality assurance practices and consistent error handling and logging procedures. To cover failures, integrate the transaction options into the CCI for maintaining data consistency and rolling back procedures as well.
- Configuration Problems: Review all of the configuration settings for all the applications, especially connection strings and package variables. As to the deployment of packages and synchronization between environments, it is recommended to lean on SSIS package configurations.
- Security Vulnerabilities: It is important to always update the security settings and policies on the website. Unfortunately, there are no videos available in SSIS 816 and so; the following advanced issues need to be managed to minimize risks: Data encryption Risk-based access control.
- Integration Challenges: Check compatibility with the other SQL Server components to validate SSIS compatibility. Introduce tested integrations gradually in Dev/QA environments before putting them in production.
Best Practices for Maximizing SSIS 816
- Regular Updates: You should upgrade your SSIS environment with other editions of Microsoft’s software updates or patches if any. This lets you enjoy the newest functionalities and patches to any susceptibilities found within the framework.
- Comprehensive Testing: When using any of the SSIS initialized stored procedures or creating any SSIS packages, always ensure that you try them out on a development or staging environment before running them on the production servers. This helps detect possible glitches which if not addressed earlier would later lead to complications and delay of the project.
- Efficient Resource Management: Monitor and manage resources effectively. Allocate sufficient memory and processing power to your SSIS tasks to avoid performance bottlenecks.
Use of Variables and Parameters:
Use variables and parameters to gain more flexibility for the further deposits and easier maintainability of your SSIS packages. This also makes it easy and efficient to transfer packages from one environment to another.
- Documentation and Logging: It is recommended to keep a detailed record of all SSIS packages that are in existence. Use extensive logging regarding executing packages so that problems can be detected easily and quickly.
- Security Best Practices: Organizations should ensure the use of minimal levels of privileged access, encryption of sensitive information, and reviewing access rights on a regular basis.
Conclusion
Without question, SSIS 816 is the tool of the future in the realm of data integration and management of the workflow. Incorporating all the above mentioned features along with performance and scalability it has become an indispensable tool for business planning to enhance their data handling capabilities. Analyzing data with the help of SSIS 816 increases its quality and improves organizational productivity while saving considerable funds. For practicing SSIS professionals as well as amateurs, It provides all the features and working, which helps you to go to the next level of your data operations.
Also Read: Master 127.0.0.1:62893
FAQs
1. What is an SSIS package used for?
An SSIS package is used for data integration, transformation, and workflow automation in SQL Server.
2. What tool is SSIS?
SSIS is a data integration and ETL (Extract, Transform, Load) tool within Microsoft SQL Server.
3. What is SSIS in ASP.NET?
In ASP.NET, SSIS is used for managing and integrating data from various sources to SQL Server databases.
Understanding Semantic Analysis NLP
By disambiguating words and assigning the most appropriate sense, we can enhance the accuracy and clarity of language processing tasks. It is useful for extracting vital information from the text to enable computers to achieve human-level accuracy in the analysis of text. Semantic analysis is very widely used in systems like chatbots, search engines, text analytics systems, and machine translation systems. In the evolving landscape of NLP, semantic analysis has become something of a secret weapon.
Semantic analysis is a powerful tool for understanding and interpreting human language in various applications. However, it comes with its own set of challenges and limitations that can hinder the accuracy and efficiency of language processing systems. Semantic similarity is the measure of how closely two texts or terms are related in meaning.
Semantic video analysis & content search uses machine learning and natural language processing to make media clips easy to query, discover and retrieve. It can also extract and classify relevant information from within videos themselves. The majority of the semantic analysis stages presented apply to the process of data understanding. Semantic analysis is a key area of study within the field of linguistics that focuses on understanding the underlying meanings of human language. NLP is transforming the way businesses approach data analysis, providing valuable insights that were previously impossible to obtain. With the rise of unstructured data, the importance of NLP in BD Insights will only continue to grow.
That is why the task to get the proper meaning of the sentence is important. To know the meaning of Orange in a sentence, we need to know the words around it. It is generally acknowledged that the ability to work with text on a semantic basis is essential to modern information retrieval systems.
This type of investigation requires understanding complex sentences, which convey nuance. Among these techniques, semantic and syntactic analysis play an important role. Although they both deal with understanding language, they operate on different levels and serve distinct objectives.
We have learnt how a parser constructs parse trees in the syntax analysis phase. The plain parse-tree constructed in that phase is generally of no use for a compiler, as it does not carry any information of how to evaluate the tree. The productions of context-free grammar, which makes the rules of the language, do not accommodate how to interpret them. For example, if you say “call mom” into a voice recognition system, it uses semantic analysis to understand that you want to make a phone call to your mother.
Offering a variety of functionalities, these tools simplify the process of extracting meaningful insights from raw text data. These three techniques – lexical, syntactic, and pragmatic semantic analysis – are not just the bedrock of NLP but have profound implications and uses in Artificial Intelligence. You can foun additiona information about ai customer service and artificial intelligence and NLP. In the sentence, “It’s cold here”, the ‘here’ is highly dependent on context. Much like choosing the right outfit for an event, selecting the suitable semantic analysis tool for your NLP project depends on a variety of factors. And remember, the most expensive or popular tool isn’t necessarily the best fit nlp semantic analysis for your needs.
In addition, the use of semantic analysis in UX research makes it possible to highlight a change that could occur in a market. Antonyms refer to pairs of lexical terms that have contrasting meanings or words that have close to opposite meanings. After understanding the theoretical aspect, it’s all about putting it to test in a real-world scenario. Training your models, testing them, and improving them in a rinse-and-repeat cycle will ensure an increasingly accurate system.
Using Syntactic analysis, a computer would be able to understand the parts of speech of the different words in the sentence. Based on the understanding, it can then try and estimate the meaning of the sentence. In the case of the above example (however ridiculous it might be in real life), there is no conflict about the interpretation. In addition, semantic analysis ensures that the accumulation of keywords is even less of a deciding factor as to whether a website matches a search query. Instead, the search algorithm includes the meaning of the overall content in its calculation.
In this example, LSA is applied to a set of documents after creating a TF-IDF representation. Not only could a sentence be written in different ways and still convey the same meaning, but even lemmas — a concept that is supposed to be far less ambiguous — can carry different meanings. It is a mathematical system for studying the interaction of functional abstraction and functional application.
Introduction to Content Semantic Analysis
This mapping is based on 1693 studies selected as described in the previous section. The lower number of studies in the year 2016 can be assigned to the fact that the last searches were conducted in February 2016. Attribute grammar is a medium to provide semantics to the context-free grammar and it can help specify the syntax and semantics of a programming language. Attribute grammar (when viewed as a parse-tree) can pass values or information among the nodes of a tree.
This can be a useful tool for semantic search and query expansion, as it can suggest synonyms, antonyms, or related terms that match the user’s query. For example, searching for “car” could yield “automobile”, “vehicle”, or “transportation” as possible expansions. There are several methods for computing semantic metadialog.com similarity, such as vector space models, word embeddings, ontologies, and semantic networks. Vector space models represent texts or terms as numerical vectors in a high-dimensional space and calculate their similarity based on their distance or angle. Word embeddings use neural networks to learn low-dimensional and dense representations of words that capture their semantic and syntactic features.
Organizations keep fighting each other to retain the relevance of their brand. There is no other option than to secure a comprehensive engagement with your customers. Businesses can win their target customers’ hearts only if they can match their expectations with the most relevant solutions. Beyond semantics, pragmatics considers how language functions in communication. Semantic ambiguity arises from polysemy (multiple related meanings) and homonymy (unrelated meanings). Polysemous words, like “bat” (a flying mammal or a sports equipment), challenge algorithms.
Semantic analysis is typically performed after the syntax analysis (also known as parsing) stage of the compiler design process. The syntax analysis generates an Abstract Syntax Tree (AST), which is a tree representation of the source code’s structure. The primary goal of semantic analysis is to catch any errors in your code that are not related to syntax. While the syntax of your code might be perfect, it’s still possible for it to be semantically incorrect. Semantic analysis checks your code to ensure it’s logically sound and performs operations such as type checking, scope checking, and more. Semantic analysis is a vital component in the compiler design process, ensuring that the code you write is not only syntactically correct but also semantically meaningful.
In this task, we try to detect the semantic relationships present in a text. In the formula, A is the supplied m by n weighted matrix of term frequencies in a collection of text where m is the number of unique terms, and n is the number of documents. T is a computed m by r matrix of term vectors where r is the rank of A—a measure of its unique dimensions ≤ min(m,n). S is a computed r by r diagonal matrix of decreasing singular values, and D is a computed n by r matrix of document vectors.
The syntactic analysis would scrutinize this sentence into its constituent elements (noun, verb, preposition, etc.) and analyze how these parts relate to one another grammatically. A pair of words can be synonymous in one context but may be not synonymous in other contexts under elements of semantic analysis. Relationship extraction is the task of detecting the semantic relationships present in a text. Relationships usually involve two or more entities which can be names of people, places, company names, etc.
Sentiment Analysis: What’s with the Tone? – InfoQ.com
Sentiment Analysis: What’s with the Tone?.
Posted: Tue, 27 Nov 2018 08:00:00 GMT [source]
For example, we want to find out the names of all locations mentioned in a newspaper. Semantic analysis would be an overkill for such an application and syntactic analysis does the job just fine. You see, the word on its own matters less, and the words surrounding it matter more for the interpretation. A semantic analysis algorithm needs to be trained with a larger corpus of data to perform better. That leads us to the need for something better and more sophisticated, i.e., Semantic Analysis.
Join over 22 million students in learning with our Vaia App
A company can scale up its customer communication by using semantic analysis-based tools. It could be BOTs that act as doorkeepers or even on-site semantic search engines. By allowing customers to “talk freely”, without binding up to a format – a firm can gather significant volumes of quality data.
Dandelion API is a set of semantic APIs to extract meaning and insights from texts in several languages (Italian, English, French, German and Portuguese). It’s optimized to perform text mining and text analytics for short texts, such as tweets and other social media. The next level is the syntactic level, that includes representations based on word co-location or part-of-speech tags. The most complete representation level is the semantic level and includes the representations based on word relationships, as the ontologies. An analysis of the meaning framework of a website also takes place in search engine advertising as part of online marketing.
Semantic analysis simplifies text understanding by breaking down the complexity of sentences, deriving meanings from words and phrases, and recognizing relationships between them. Its intertwining with sentiment analysis aids in capturing customer sentiments more accurately, presenting a treasure trove of useful insight for businesses. Its significance cannot be overlooked for NLP, as it paves the way for the seamless interpreting of context, synonyms, homonyms and much more. In semantic analysis with machine learning, computers use word sense disambiguation to determine which meaning is correct in the given context. Other semantic analysis techniques involved in extracting meaning and intent from unstructured text include coreference resolution, semantic similarity, semantic parsing, and frame semantics.
- Sign up to receive periodic updates from us with new tools, resources and articles.
- Currently, there are several variations of the BERT pre-trained language model, including BlueBERT, BioBERT, and PubMedBERT, that have applied to BioNER tasks.
- The reduced-dimensional space represents the words and documents in a semantic space.
- What we do in co-reference resolution is, finding which phrases refer to which entities.
MindManager® helps individuals, teams, and enterprises bring greater clarity and structure to plans, projects, and processes. It provides visual productivity tools and mind mapping software to help take you and your organization to where you want to be. However, even the more complex models use a similar strategy to understand how words relate to each other and provide context. These tools enable computers (and, therefore, humans) to understand the overarching themes and sentiments in vast amounts of data.
But before getting into the concept and approaches related to meaning representation, we need to understand the building blocks of semantic system. Thus, the ability of a machine to overcome the ambiguity involved in identifying the meaning of a word based on its usage and context is called Word Sense Disambiguation. QuestionPro, a survey and research platform, might have certain features or functionalities that could complement or support the semantic analysis process.
LSA is primarily used for concept searching and automated document categorization. However, it’s also found use in software engineering (to understand source code), publishing (text summarization), search engine optimization, and other applications. The same word can have different meanings in different contexts, and it can be difficult for machines to accurately interpret the intended meaning. Whether it is Siri, Alexa, or Google, they can all understand human language (mostly). Today we will be exploring how some of the latest developments in NLP (Natural Language Processing) can make it easier for us to process and analyze text. The system using semantic analysis identifies these relations and takes various symbols and punctuations into account to identify the context of sentences or paragraphs.
Semantic analysis surely instills NLP with the intellect of context and meaning. It’s high time we master the techniques and methodologies involved if we’re seeking to reap the benefits of the fast-tracked technological world. Content is today analyzed by search engines, semantically and ranked accordingly.
Semantic analysis, on the other hand, is crucial to achieving a high level of accuracy when analyzing text. Based on them, the classification model can learn to generalise the classification to words that have not previously occurred in the training set. Maps are essential to Uber’s cab services of destination search, routing, and prediction of the estimated arrival time (ETA). Along with services, it also improves the overall experience of the riders and drivers. The idiom “break a leg” is often used to wish someone good luck in the performing arts, though the literal meaning of the words implies an unfortunate event. 1.25 is not an integer literal, and there is no implicit conversion from 1.25 to int, so this statement does not make sense.
To decide, and to design the right data structure for your algorithms is a very important step. The Parser is a complex software module that understands such type of Grammars, and check that every rule is respected using advanced algorithms and data semantic analysis example structures. I can’t help but suggest to read more about it, including my previous articles. It’s quite likely (although it depends on which language it’s being analyzed) that it will reject the whole source code because that sequence is not allowed.
We must read this line character after character, from left to right, and tokenize it in meaningful pieces. It has to do with the Grammar, that is the syntactic rules the entire language is built on. It’s called front-end because it basically is an interface between the source code written by a developer, and the transformation that this code will go through in order to become executable. In the above sentence, the speaker is talking either about Lord Ram or about a person whose name is Ram.
Semantic analysis is elevating the way we interact with machines, making these interactions more human-like and efficient. This is particularly seen in the rise of chatbots and voice assistants, which are able to understand and respond to user queries more accurately thanks to advanced semantic processing. Overall, the integration of semantics and data science has the potential to revolutionize the way we analyze and interpret large datasets.
We will delve into its core concepts, explore powerful techniques, and demonstrate their practical implementation through illuminating code examples using the Python programming language. Get ready to unravel the power of semantic analysis and unlock the true potential of your text data. The aim of this approach is to automatically process certain requests from your target audience in real time. Thanks to language interpretation, chatbots can deliver a satisfying digital experience without you having to intervene. In addition, semantic analysis helps you to advance your Customer Centric approach to build loyalty and develop your customer base. As a result, you can identify customers who are loyal to your brand and make them your ambassadors.
NER is widely used in various NLP applications, including information extraction, question answering, text summarization, and sentiment analysis. By accurately identifying and categorizing named entities, NER enables machines to gain a deeper understanding of text and extract relevant information. Driven by the analysis, tools emerge as pivotal assets in crafting customer-centric strategies and automating processes. Moreover, they don’t just parse text; they extract valuable information, discerning opposite meanings and extracting relationships between words. Efficiently working behind the scenes, semantic analysis excels in understanding language and inferring intentions, emotions, and context.
When using static representations, words are always represented in the same way. For example, if the word “rock” appears in a sentence, it gets an identical representation, regardless of whether we mean a music genre or mineral material. The word is assigned a vector that reflects its average meaning over the training corpus. The very first reason is that with the help of meaning representation the linking of linguistic elements to the non-linguistic elements can be done.
In this section, we explore the multifaceted landscape of NLP within the context of content semantic analysis, shedding light on its methodologies, challenges, and practical applications. Semantic analysis, also known as textual or content analysis, plays a pivotal role in extracting meaning from unstructured textual data. By deciphering the underlying semantics, we can unlock valuable insights, improve search algorithms, enhance natural language understanding, and enable more effective information retrieval.
For instance the sentence “… is supposed to be…” (Schmidt par. 2 ) in the article ‘A Christmas gift’ makes less meaning unless the root word ‘suppose’ is replaced with ‘supposed’. An analysis of the Twitter conversations of all of the U.K.’s Members of Parliament in 2013 highlighted the top issues providing a look at what is being said, when and by whom. They involve creating a set of rules that the machine follows to interpret the meaning of words and sentences. Syntax analysis and Semantic analysis can give the same output for simple use cases (eg. parsing). However, for more complex use cases (e.g. Q&A Bot), Semantic analysis gives much better results.
From our systematic mapping data, we found that Twitter is the most popular source of web texts and its posts are commonly used for sentiment analysis or event extraction. Wimalasuriya and Dou [17] present a detailed literature review of ontology-based information extraction. Bharathi and Venkatesan [18] present a brief description of several studies that use external knowledge sources as background knowledge for document clustering. In conclusion, Semantic Analysis is a crucial aspect of Artificial Intelligence and Machine Learning, playing a pivotal role in the interpretation and understanding of human language. It’s a complex process that involves the analysis of words, sentences, and text to understand the meaning and context. The
process involves contextual text mining that identifies and extrudes
subjective-type insight from various data sources.
What is the difference between syntactic analysis and semantic analysis?
It is thus important to load the content with sufficient context and expertise. On the whole, such a trend has improved the general content quality of the internet. The purpose of semantic analysis is to draw exact meaning, or you can say dictionary meaning from the text.
- Artificial intelligence, like Google’s, can help you find areas for improvement in your exchanges with your customers.
- Equally crucial has been the surfacing of semantic role labeling (SRL), another newer trend observed in semantic analysis circles.
- Understanding the Concept of Reverse and Countermand In any decision-making process, there comes a…
- In this section, we will explore various applications of content semantic analysis without explicitly stating the section title.
- Other relevant terms can be obtained from this, which can be assigned to the analyzed page.
Thanks to this SEO tool, there’s no need for human intervention in the analysis and categorization of any information, however numerous. To understand the importance of semantic analysis in your customer relationships, you first need to know what it is and how it works. The reduced-dimensional space represents the words and documents in a semantic space. Their attempts to categorize student reading comprehension relate to our goal of categorizing sentiment. This text also introduced an ontology, and “semantic annotations” link text fragments to the ontology, which we found to be common in semantic text analysis. Our cutoff method allowed us to translate our kernel matrix into an adjacency matrix, and translate that into a semantic network.
This approach is built on the basis of and by imitating the cognitive and decision-making processes running in the human brain. For example, the advent of deep learning technologies has instigated a paradigm shift towards advanced semantic tools. With these tools, it’s feasible to delve deeper into the linguistic structures and extract more meaningful insights from a wide array of textual data. It’s not just about isolated words anymore; it’s about the context and the way those words interact to build meaning.
Thus, after the previous Tokens sequence is given to the Parser, the latter would understand that a comma is missing and reject the source code. Because there must be a syntactic rule in the Grammar definition that clarify how as assignment statement (such as the one in the example) must be made in terms of Tokens. In different words, front-end is the stage of the compilation where the source code is checked for errors. There can be lots of different error types, as you certainly know if you’ve written code in any programming language. After analyzing the messages, the chatbot will classify all exchanges with customers by theme, intention or risk.
No errors would be reported in this step, simply because all characters are valid, as well as all subgroups of them (e.g., Object, int, etc.). Thus, the code in the example would pass the Lexical Analysis, but then would be rejected by the Parser. To tokenize is “just” about splitting a stream of characters in groups, and output a sequence Chat GPT of Tokens. To parse is “just” about understanding if the sequence of Tokens is in the right order, and accept or reject it. Each Token is a pair made by the lexeme (the actual character sequence), and a logical type assigned by the Lexical Analysis. These types are usually members of an enum structure (or Enum class, in Java).
It has elevated the way we interpret data and powered enhancements in AI and Machine Learning, making it an integral part of modern technology. However, while it’s possible to expand the Parser so that it also check errors like this one (whose name, by the way, is “typing error”), this approach does not make sense. A sentence has a main logical concept conveyed which we can name as the predicate.
It captures some of the essential, common features of a wide variety of programming languages. As it directly supports abstraction, it is a more natural model of universal computation than a Turing machine. This means replacing a word with another existing word similar in letter composition and/or sound but semantically incompatible with the context.
Its potential goes beyond simple data sorting into uncovering hidden relations and patterns. All factors considered, Uber uses semantic analysis to analyze and address customer support tickets submitted by riders on the Uber platform. In the field of e-commerce, content semantic analysis has been instrumental in improving product recommendations. By analyzing customer reviews, feedback, and product descriptions, businesses can gain valuable insights into customer preferences and tailor their recommendations accordingly.
Semantic analysis software can be especially useful if you are combining large data sets. Open Congress and Sunlight Labs both have a variety of downloadable data at the state level, and even some local data. Semantic analysis software can be especially useful when combining large data sets. When it comes https://chat.openai.com/ to semantic software, there are a full range of tools, from getting a quick look at the prominence of key words with a word cloud to designing software to filter your content. Semantic Analysis has a wide range of applications in various fields, from search engines to voice recognition software.
However, due to the vast complexity and subjectivity involved in human language, interpreting it is quite a complicated task for machines. Semantic Analysis of Natural Language captures the meaning of the given text while taking into account context, logical structuring of sentences and grammar roles. Moreover, analyzing customer reviews, feedback, or satisfaction surveys helps understand the overall customer experience by factoring in language tone, emotions, and even sentiments.
One can train machines to make near-accurate predictions by providing text samples as input to semantically-enhanced ML algorithms. Machine learning-based semantic analysis involves sub-tasks such as relationship extraction and word sense disambiguation. Semantic analysis is defined as a process of understanding natural language (text) by extracting insightful information such as context, emotions, and sentiments from unstructured data.
Type checking helps prevent various runtime errors, such as type conversion errors, and ensures that the code adheres to the language’s type system. In the case of syntactic analysis, the syntax of a sentence is used to interpret a text. In the case of semantic analysis, the overall context of the text is considered during the analysis. Natural Language Processing or NLP is a branch of computer science that deals with analyzing spoken and written language.
Here, the values of non-terminals E and T are added together and the result is copied to the non-terminal E. Each attribute has well-defined domain of values, such as integer, float, character, string, and expressions. All rights are reserved, including those for text and data mining, AI training, and similar technologies. One of the advantages of statistical methods is that they can handle large amounts of data quickly and efficiently. However, they can also be prone to errors, as they rely on patterns and trends that may not always be accurate or reliable. This allows companies to enhance customer experience, and make better decisions using powerful semantic-powered tech.
Here the generic term is known as hypernym and its instances are called hyponyms. It makes the customer feel “listened to” without actually having to hire someone to listen. The idiom “break a leg” is often used to wish someone good luck in the performing arts, though the literal meaning of the words implies an unfortunate event. In the sentence “John gave Mary a book”, the frame is a ‘giving’ event, with frame elements “giver” (John), “recipient” (Mary), and “gift” (book). Once the study has been administered, the data must be processed with a reliable system. Semantic analysis applied to consumer studies can highlight insights that could turn out to be harbingers of a profound change in a market.
7 Ways To Use Semantic SEO For Higher Rankings – Search Engine Journal
7 Ways To Use Semantic SEO For Higher Rankings.
Posted: Mon, 14 Mar 2022 07:00:00 GMT [source]
For example, the search engines must differentiate between individual meaningful units and comprehend the correct meaning of words in context. Social platforms, product reviews, blog posts, and discussion forums are boiling with opinions and comments that, if collected and analyzed, are a source of business information. The more they’re fed with data, the smarter and more accurate they become in sentiment extraction. On the other hand, constituency parsing segments sentences into sub-phrases. Applying semantic analysis in natural language processing can bring many benefits to your business, regardless of its size or industry.
So, in this part of this series, we will start our discussion on Semantic analysis, which is a level of the NLP tasks, and see all the important terminologies or concepts in this analysis. This could be from customer interactions, reviews, social media posts, or any relevant text sources. Some of the noteworthy ones include, but are not limited to, RapidMiner Text Mining Extension, Google Cloud NLP, Lexalytics, IBM Watson NLP, Aylien Text Analysis API, to name a few. Semantic analysis has a pivotal role in AI and Machine learning, where understanding the context is crucial for effective problem-solving. Treading the path towards implementing semantic analysis comprises several crucial steps.
Content semantic analysis Unlocking Insights: A Guide to Content Semantic Analysis

In some sense, the primary objective of the whole front-end is to reject ill-written source codes. Lexical Analysis is just the first of three steps, and it checks correctness at the character level. The aim of this system is to provide relevant results to Internet users when they carry out searches. This algorithm also helps companies to develop their visibility through SEO. It’s in the interests of these entities to produce quality content on their web pages. In fact, Google has also deployed its analysis system with a view to perfecting its understanding of the content of Internet users’ queries.
It provides critical context required to understand human language, enabling AI models to respond correctly during interactions. This is particularly significant for AI chatbots, which use semantic analysis to interpret customer queries accurately and respond effectively, leading to enhanced customer satisfaction. Semantic analysis allows for a deeper understanding of user preferences, enabling personalized recommendations in e-commerce, content curation, and more. Insights derived from data also help teams detect areas of improvement and make better decisions. Semantic Analysis is often compared to syntactic analysis, but the two are fundamentally different.
In simple terms, it’s the process of teaching machines how to understand the meaning behind human language. As we delve further in the intriguing world of NLP, semantics play a crucial role from providing context to intricate natural language processing tasks. As discussed in previous articles, NLP cannot decipher ambiguous words, which are words that can have more than one meaning in different contexts. Semantic analysis is key to contextualization that helps disambiguate language data so text-based NLP applications can be more accurate. These chatbots act as semantic analysis tools that are enabled with keyword recognition and conversational capabilities.
Improved Machine Learning Models:
By referring to this data, you can produce optimized content that search engines will reference. What’s more, you need to know that semantic and syntactic analysis are inseparable in the Automatic Natural Language Processing or NLP. In fact, it’s an approach aimed at improving better understanding of natural language. We can any of the below two semantic analysis techniques depending on the type of information you would like to obtain from the given data. Therefore, the goal of semantic analysis is to draw exact meaning or dictionary meaning from the text.
Social media sentiment analysis: Benefits and guide for 2024 – Sprout Social
Social media sentiment analysis: Benefits and guide for 2024.
Posted: Wed, 21 Aug 2024 07:00:00 GMT [source]
This technology can be used to create interactive dashboards that allow users to explore data in real-time, providing valuable insights into customer behavior, market trends, and more. The syntactic analysis makes sure that sentences are well-formed in accordance with language rules by concentrating on the grammatical structure. Semantic analysis, on the other hand, explores meaning by evaluating the language’s importance and context. Syntactic analysis, also known as parsing, involves the study of grammatical errors in a sentence. Semantic Analysis is the process of deducing the meaning of words, phrases, and sentences within a given context.
You can foun additiona information about ai customer service and artificial intelligence and NLP. In this way, the customer’s message will appear under “Dissatisfaction” so that the company’s internal teams can act quickly to correct the situation. What we do in co-reference resolution is, finding which phrases refer to which entities. Here we need to find all the references to an entity within a text document. There are also words that such as ‘that’, ‘this’, ‘it’ which may or may not refer to an entity. We should identify whether they refer to an entity or not in a certain document.
Your school may already provide access to MATLAB, Simulink, and add-on products through a campus-wide license. •Provides native support for reading in several classic file formats •Supports the export from document collections to term-document matrices. Carrot2 is an open Source search Results Clustering Engine with high quality clustering algorithmns and esily integrates in both Java and non Java platforms. Semantic Analysis is related to creating representations for the meaning of linguistic inputs. It deals with how to determine the meaning of the sentence from the meaning of its parts.
Upon parsing, the analysis then proceeds to the interpretation step, which is critical for artificial intelligence algorithms. Text analytics dig through your data in real time to reveal hidden patterns, trends and relationships between different pieces of content. Use text analytics to gain insights into customer and user behavior, analyze trends in social media and e-commerce, find the root causes of problems and more. The use of Wikipedia is followed by the use of the Chinese-English knowledge database HowNet [82]. As well as WordNet, HowNet is usually used for feature expansion [83–85] and computing semantic similarity [86–88]. They are created by analyzing a body of text and representing each word, phrase, or entire document as a vector in a high-dimensional space (similar to a multidimensional graph).
Semantic analysis in NLP is about extracting the deeper meaning and relationships between words, enabling machines to comprehend and work with human language in a more meaningful way. But before deep dive into the concept and approaches related to meaning representation, firstly we have to understand the building blocks of the semantic system. From a technological standpoint, NLP involves a range of techniques and tools that enable computers to understand and generate human language. These include methods such as tokenization, part-of-speech tagging, syntactic parsing, named entity recognition, sentiment analysis, and machine translation. Each of these techniques plays a crucial role in enabling chatbots to understand and respond to user queries effectively. From a linguistic perspective, NLP involves the analysis and understanding of human language.
Syntax
As semantic analysis evolves, it holds the potential to transform the way we interact with machines and leverage the power of language understanding across diverse applications. Semantic analysis, a crucial component of natural language processing https://chat.openai.com/ (NLP), plays a pivotal role in extracting meaning from textual content. By delving into the intricate layers of language, NLP algorithms aim to decipher context, intent, and relationships between words, phrases, and sentences.
In that case it would be the example of homonym because the meanings are unrelated to each other. Transparency in AI algorithms, for one, has increasingly become a focal point of attention. Semantic analysis is poised to play a key role in providing this interpretability. Don’t fall in the trap of ‘one-size-fits-all.’ Analyze your project’s special characteristics to decide if it calls for a robust, full-featured versatile tool or a lighter, task-specific one. Remember, the best tool is the one that gets your job done efficiently without any fuss.
The arguments for the predicate can be identified from other parts of the sentence. Some methods use the grammatical classes whereas others use unique methods to name these arguments. The identification of the predicate and the arguments for that predicate is known as semantic role labeling. Extensive business analytics enables an organization to gain precise insights into their customers. Consequently, they can offer the most relevant solutions to the needs of the target customers. Creating a concept vector from a text can be done with a Vectorizer, implemented in the class be.vanoosten.esa.tools.Vectorizer.
Types of Internet advertising include banner, semantic, affiliate, social networking, and mobile. In addition to the top 10 competitors positioned on the subject of your text, YourText.Guru will give you an optimization score and a danger score. Find out all you need to know about this indispensable marketing and SEO technique.
- Thanks to language interpretation, chatbots can deliver a satisfying digital experience without you having to intervene.
- Meaning representation can be used to reason for verifying what is true in the world as well as to infer the knowledge from the semantic representation.
- Their attempts to categorize student reading comprehension relate to our goal of categorizing sentiment.
- From a linguistic perspective, NLP involves the analysis and understanding of human language.
Semantic analysis starts with lexical semantics, which studies individual words’ meanings (i.e., dictionary definitions). Semantic analysis is an important subfield of linguistics, the systematic scientific investigation of the properties and characteristics of natural human language. QuestionPro often includes text analytics features that perform sentiment analysis on open-ended survey responses. While not a full-fledged semantic analysis tool, it can help understand the general sentiment (positive, negative, neutral) expressed within the text. We could also imagine that our similarity function may have missed some very similar texts in cases of misspellings of the same words or phonetic matches.
Semantic analysis starts with lexical semantics, which studies individual words’ meanings (i.e., dictionary definitions). Semantic analysis then examines relationships between individual words and analyzes the meaning of words that come together to form a sentence. Semantic parsing is the process of mapping natural language sentences to formal meaning representations.
Systematic literature review is a formal literature review adopted to identify, evaluate, and synthesize evidences of empirical results in order to answer a research question. The use of features based on WordNet has been applied with and without good results [55, 67–69]. Besides, WordNet can support the computation of semantic similarity [70, 71] and the evaluation of the discovered knowledge [72].
Search Engines:
It enables machines to understand, interpret, and respond to human language in a way that feels natural and intuitive. Semantic analysis is the process of finding the meaning of content in natural language. Over the years, in subjective detection, the features extraction progression from curating features by hand to automated features learning.
Understanding the results of a UX study with accuracy and precision allows you to know, in detail, your customer avatar as well as their behaviors (predicted and/or proven ). This data is the starting point for any strategic plan (product, sales, marketing, etc.). I’m Tim, Chief Creative Officer for Penfriend.ai
I’ve been involved with SEO and Content for over a decade at this point. I’m also the person designing the product/content process for how Penfriend actually works. Packed with profound potential, it’s a goldmine that’s yet to be fully tapped.
TextOptimizer – The Semantic Analysis-Oriented Tool
The use of semantic analysis in the processing of web reviews is becoming increasingly common. This system is infallible for identify priority areas for improvement based on feedback from buyers. At present, the semantic analysis tools Machine Learning algorithms are the most effective, as well as Natural Language Processing technologies. One of the most common applications of semantics in data science is natural language processing (NLP). NLP is a field of study that focuses on the interaction between computers and human language.
Semantic analysis employs various methods, but they all aim to comprehend the text’s meaning in a manner comparable to that of a human. This can entail figuring out the text’s primary ideas and themes and their connections. In-Text Classification, our aim is to label the text according to the insights we intend to gain from the textual data.
A sentence that is syntactically correct, however, is not always semantically correct. For Example, you could analyze the keywords in a bunch of tweets that have been categorized as “negative” and detect which words or topics are mentioned most often. For Example, Tagging Twitter mentions by sentiment to get a sense of how customers feel about your product and can identify unhappy customers in real-time. Homonymy and polysemy deal with the closeness or relatedness of the senses between words. It is also sometimes difficult to distinguish homonymy from polysemy because the latter also deals with a pair of words that are written and pronounced in the same way.
As a result, the use of LSI has significantly expanded in recent years as earlier challenges in scalability and performance have been overcome. This matrix is also common to standard semantic models, though it is not necessarily explicitly expressed as a matrix, since the mathematical properties of matrices are semantic analysis example not always used. But to extract the “substantial marrow”, it is still necessary to know how to analyze this dataset. Semantic analysis makes it possible to classify the different items by category. Homonymy refers to the case when words are written in the same way and sound alike but have different meanings.
With the help of meaning representation, unambiguous, canonical forms can be represented at the lexical level. Continue reading this blog to learn more about semantic analysis and how it can work with examples. According to a 2020 survey by Seagate technology, around 68% of the unstructured and text data that flows into the top 1,500 global companies (surveyed) goes unattended and unused.
As we discussed, the most important task of semantic analysis is to find the proper meaning of the sentence. Understanding each tool’s strengths and weaknesses is crucial in leveraging their potential to the fullest. Stay tuned as we dive deep into the offerings, advantages, and potential downsides of these semantic analysis tools. Semantic Analysis uses the science of meaning in language to interpret the sentiment, which expands beyond just reading words and numbers. This provides precision and context that other methods lack, offering a more intricate understanding of textual data. For example, it can interpret sarcasm or detect urgency depending on how words are used, an element that is often overlooked in traditional data analysis.
Semantic Analysis: Catch Them All!
The vectorizer has a vectorize(String text) method, which transforms the text into a concept vector (be.vanoosten.esa.tools.ConceptVector). Basically, the text is Chat GPT tokenized and searched for in the term-to-concept index. The result is a list of Wikipedia articles, along with their numeric similarity to the vectorized text.
The process enables computers to identify and make sense of documents, paragraphs, sentences, and words as a whole. NER is a key information extraction task in NLP for detecting and categorizing named entities, such as names, organizations, locations, events, etc.. NER uses machine learning algorithms trained on data sets with predefined entities to automatically analyze and extract entity-related information from new unstructured text. NER methods are classified as rule-based, statistical, machine learning, deep learning, and hybrid models.
Speaking about business analytics, organizations employ various methodologies to accomplish this objective. In that regard, sentiment analysis and semantic analysis are effective tools. By applying these tools, an organization can get a read on the emotions, passions, and the sentiments of their customers.
Sentiment Analysis: How To Gauge Customer Sentiment (2024) – Shopify
Sentiment Analysis: How To Gauge Customer Sentiment ( .
Posted: Thu, 11 Apr 2024 07:00:00 GMT [source]
For example, Google uses semantic analysis for its advertising and publishing tool AdSense to determine the content of a website that best fits a search query. Google probably also performs a semantic analysis with the keyword planner if the tool suggests suitable search terms based on an entered URL. The more accurate the content of a publisher’s website can be determined with regard to its meaning, the more accurately display or text ads can be aligned to the website where they are placed.
What Is Semantic Analysis?
Semantic analysis techniques and tools allow automated text classification or tickets, freeing the concerned staff from mundane and repetitive tasks. In the larger context, this enables agents to focus on the prioritization of urgent matters and deal with them on an immediate basis. It also shortens response time considerably, which keeps customers satisfied and happy. Semantic analysis tech is highly beneficial for the customer service department of any company. Moreover, it is also helpful to customers as the technology enhances the overall customer experience at different levels.
Vaia is a globally recognized educational technology company, offering a holistic learning platform designed for students of all ages and educational levels. We offer an extensive library of learning materials, including interactive flashcards, comprehensive textbook solutions, and detailed explanations. The cutting-edge technology and tools we provide help students create their own learning materials. StudySmarter’s content is not only expert-verified but also regularly updated to ensure accuracy and relevance.
It supports moderation of users’ comments published on the Polish news portal called Wirtualna Polska. In particular, it aims at finding comments containing offensive words and hate speech. As Igor Kołakowski, Data Scientist at WEBSENSA points out, this representation is easily interpretable for humans. It is also accepted by classification algorithms like SVMs or random forests. Therefore, this simple approach is a good starting point when developing text analytics solutions.
Another example is “Both times that I gave birth…” (Schmidt par. 1) where one may not be sure of the meaning of the word ‘both’ it can mean; twice, two or double. In real application of the text mining process, the participation of domain experts can be crucial to its success. However, the participation of users (domain experts) is seldom explored in scientific papers. The difficulty inherent to the evaluation of a method based on user’s interaction is a probable reason for the lack of studies considering this approach.
Idiomatic expressions are challenging because they require identifying idiomatic usages, interpreting non-literal meanings, and accounting for domain-specific idioms. Would you like to know if it is possible to use it in the context of a future study? It is precisely to collect this type of feedback that semantic analysis has been adopted by UX researchers.
Researchers and practitioners continually refine techniques to unlock deeper insights from textual data. Understanding these limitations allows us to appreciate the remarkable progress made while acknowledging the road ahead. Semantic analysis is a mechanism that allows machines to understand a sequence of words in the same way that humans understand it. This depends on understanding what the words mean and what they refer to based on the context and domain, which can sometimes be ambiguous. Research on the user experience (UX) consists of studying the needs and uses of a target population towards a product or service. Using semantic analysis in the context of a UX study, therefore, consists in extracting the meaning of the corpus of the survey.
Tokenization is the process of breaking down a text into smaller units called tokens. Tokenization is a fundamental step in NLP as it enables machines to understand and process human language. Equally crucial has been the surfacing of semantic role labeling (SRL), another newer trend observed in semantic analysis circles. SRL is a technique that augments the level of scrutiny we can apply to textual data as it helps discern the underlying relationships and roles within sentences. Semantic analysis is a key player in NLP, handling the task of deducing the intended meaning from language.
So the question is, why settle for an educated guess when you can rely on actual knowledge? Then it starts to generate words in another language that entail the same information. Semantic processing is when we apply meaning to words and compare/relate it to words with similar meanings. Semantic analysis techniques are also used to accurately interpret and classify the meaning or context of the page’s content and then populate it with targeted advertisements. It allows analyzing in about 30 seconds a hundred pages on the theme in question. Differences, as well as similarities between various lexical-semantic structures, are also analyzed.
Building Llama 3 LLM from scratch in code AI Beginners Guide
In the “Advanced settings”, it’s possible to fine-tune hyperparameters, such as temperature, repetition penalty, or the number of top-k tokens to consider when generating text. Training also entails exposing it to the preprocessed dataset and repeatedly updating its parameters to minimize the difference between the predicted model’s output and the actual output. This process, known as backpropagation, allows your model to learn about underlying patterns and relationships within the data. For this task, you’re in good hands with Python, which provides a wide range of libraries and frameworks commonly used in NLP and ML, such as TensorFlow, PyTorch, and Keras. These libraries offer prebuilt modules and functions that simplify the implementation of complex architectures and training procedures. Additionally, your programming skills will enable you to customize and adapt your existing model to suit specific requirements and domain-specific work.
Therefore, it’s essential to determine whether building an LLM is necessary for your needs or if an existing solution can provide the same benefits. An essential part of creating an effective training dataset is reserving a portion of the curated data for evaluating the model. Using the same data for both training and evaluation risks overfitting, where the model becomes too familiar with the training data and fails to generalize to new data. In addition, this book includes code for loading the weights of larger pretrained models for finetuning.
LLMs are trained to predict the next token in the text, so input and output pairs are generated accordingly. While this demonstration considers each word as a token for simplicity, in practice, tokenization algorithms like Byte Pair Encoding (BPE) further break down each word into subwords. Over the next five years, there was significant research focused on building better LLMs for begineers compared to transformers.
LSTM solved the problem of long sentences to some extent but it could not really excel while working with really long sentences. In 1967, a professor at MIT built the first ever NLP program Eliza to understand natural language. It uses pattern matching and substitution techniques to understand and interact with humans.
Researchers evaluated traditional language models using intrinsic methods like perplexity, bits per character, etc. These metrics track the performance on the language front i.e. how well the model is able to predict the next word. In the case of classification or regression problems, we have the true labels and predicted labels and then compare both of them to understand how well the model is performing. You might have come across the headlines that “ChatGPT failed at JEE” or “ChatGPT fails to clear the UPSC” and so on.
Numerous sectors of the economy face legal restrictions concerning the application of data and its protection. These regulations can be met using a private LLM because you are entirely in charge of the data used to train the model and the environment where it is deployed. This control assists in meeting the objectives of reducing risks stemming from non-compliance with regulations and in building the reputation of your organization as a trustworthy institution. Surprisingly, we have actually already converted our functions into graphs. If you recall, when we generate a tensor from an operation, we record the inputs to the operation in the output tensor (in .args).
Customisation and Control
Hyperparameters are the settings used to optimize the learning process of a model. Proper tuning of hyperparameters is essential for training effective and efficient models. Transformer architecture is a neural network design that relies on self-attention mechanisms to weigh the influence of different parts of the input data. It is highly parallelizable and has been revolutionary in handling sequential data, such as text, for language models. Finally, remember that the evaluation phase is not the end of the journey. Use the insights gained to refine your model’s architecture, training data, and hyperparameters.
Here, we have considered the principal types of LLMs to assist you in making the right choice. Differentiating scalars is (I hope you agree) interesting, but it isn’t exactly GPT-4. That said, with a few small modifications to our algorithm, we can extend our algorithm to handle multi-dimensional tensors like matrices and vectors. Once you can do that, you can build up to backpropagation and, eventually, to a fully functional language model.
We also stored the functions to calculate derivatives for each of the inputs in .local_derivatives which means that we know both the destination and derivative for every edge that points to a given node. Hyperparameter tuning is a very expensive process in terms of time and cost as well. 1,400B (1.4T) tokens should be used to train a data-optimal LLM of size 70B parameters. The no. of tokens used to train LLM should be 20 times more than the no. of parameters of the model. You can foun additiona information about ai customer service and artificial intelligence and NLP. Join me on an exhilarating journey as we will discuss the current state of the art in LLMs for begineers.
- We can use the results from these evaluations to prevent us from deploying a large model where we could have had perfectly good results with a much smaller, cheaper model.
- Data privacy and security in creating an LLM are critical, as they involve ensuring compliance with regulations like GDPR and preventing sensitive data leaks during the training phase.
- It has 1 million pairs of english-malay training datasets which is more than sufficient to get good accuracy and 2000 data each in validation and test datasets.
- Sometimes, people come to us with a very clear idea of the model they want that is very domain-specific, then are surprised at the quality of results we get from smaller, broader-use LLMs.
Moreover, such measures are mandatory for organizations to comply with HIPAA, PCI-DSS, and other regulations in certain industries. So, we need custom models with a better language understanding of a specific domain. A custom model can operate within its new context more accurately when trained with specialized knowledge. For instance, a fine-tuned domain-specific LLM can be used alongside semantic search to return results relevant to specific organizations conversationally. In this tutorial, we built a basic GPT-like Transformer model from scratch, trained it on a small dataset, and generated text using autoregressive decoding.
if(codePromise) return codePromise
Our approach involves creating a pipeline for automatic review of video content. This pipeline integrates NVidia Riva to convert audio tracks into text format while capturing emotional tones, and Hume AI for content analysis and review using their SDK alongside our own customized tools. These models leverage vast amounts of data and complex, deep neural networks to produce text that can be indistinguishable from text written by humans.
The Llama 3 model serves as a foundation for understanding the core concepts and components of the transformer architecture. Scaling laws in deep learning explores the relationship between compute power, dataset size, and the number of parameters for a language model. The study was initiated by OpenAI in 2020 to predict a model’s performance before training it.
Vaswani announced (I would prefer the legendary) paper “Attention is All You Need,” which used a novel architecture that they termed as “Transformer.” Once your Language Model (LLM) is ready for deployment, scaling and optimizing for production becomes crucial to handle the increased load and to ensure efficient performance. The goal is to serve a larger audience while maintaining low latency and high reliability.
- Making your own Large Language Model (LLM) is a cool thing that many big companies like Google, Twitter, and Facebook are doing.
- LLMs devour vast amounts of text, dissecting them into words, phrases, and relationships.
- It involves adjusting the parameters that govern the training process to achieve the best possible performance.
- Due to the ongoing advancements in technology, organizations are continuously looking for ways to improve their commercial proceedings, customer relations, and decision-making processes.
- Proper tuning of hyperparameters is essential for training effective and efficient models.
Streamline your LLM development process with Todoist, the ultimate task management tool to keep your project organized and on track. Prioritize tasks, set deadlines, and collaborate seamlessly, ensuring nothing falls through the cracks as you build your large language model from scratch. Data preprocessing might seem time-consuming but its importance can’t be overstressed. It ensures that your large language model learns from meaningful information alone, setting a solid foundation for effective implementation.
Learning is better with cohorts
The answers to these critical questions can be found in the realm of scaling laws. Scaling laws are the guiding principles that unveil the optimal relationship between the volume of data and the size of the model. Fine-tuning and prompt engineering allow tailoring them for specific purposes.
After training the model, evaluation becomes essential to assess its performance. Various benchmark datasets, like those on the Open LLM Leaderboard, can be used for evaluation. Multiple-choice tasks can be evaluated using prompt templates and probability distributions generated by the model.
Mixed precision training, combining 32-bit and 16-bit floating-point numbers, helps to speed up the training process. 3D parallelism, combining pipeline parallelism, model parallelism, and data parallelism, distributes the training workload across multiple GPUs. Leading AI providers have acknowledged the limitations of generic language models in specialized applications. They developed domain-specific models, including BloombergGPT, Med-PaLM 2, and ClimateBERT, to perform domain-specific tasks. Such models will positively transform industries, unlocking financial opportunities, improving operational efficiency, and elevating customer experience.
Generative AI built on a proprietary LLM is the way to go — if you know where to look – diginomica
Generative AI built on a proprietary LLM is the way to go — if you know where to look.
Posted: Thu, 30 Nov 2023 08:00:00 GMT [source]
Some of the main challenges include acquiring and preprocessing large datasets, optimizing the model architecture, managing computational resources, and ensuring the model’s ethical use. Training build LLM from scratch is a complex task that requires careful preparation and execution. By following this guide, obtaining the necessary software, data, and tools, and applying a consistent, iterative approach, you can create a powerful tool that can generate Python code from text prompts. Remember, patience and persistence are key, and the rewards of a well-trained LLM can be significant in automating code creation and understanding. They are trained on extensive datasets, enabling them to grasp diverse language patterns and structures. You can utilize pre-training models as a starting point for creating custom LLMs tailored to their specific needs.
Now, let’s examine the generated output from our 2 million-parameter Language Model. Having successfully created a single layer, we can now use it to construct multiple layers. Additionally, we will rename our model class from “ropemodel” to “Llama” as we have replicated every component of the LLaMA language model. In the original LLaMA paper, diverse open-source datasets were employed to train and evaluate the model.
Something called GPT-2 just changed your life.
After downloading the model, we provide the local directory where the model is stored, including the file name and extension. We set the maximum number of tokens in the model response and model temperature. Additionally, in the “Advanced settings”, we can customize different token sampling strategies for output generation. With fine tuning, a company can create a model specifically targeted at their business use case. “We’ll definitely work with different providers and different models,” she says.
With the advancements in LLMs today, researchers and practitioners prefer using extrinsic methods to evaluate their performance. The recommended way to evaluate LLMs is to look at how well they are performing at different tasks like problem-solving, reasoning, https://chat.openai.com/ mathematics, computer science, and competitive exams like MIT, JEE, etc. Training is the process of teaching your model using the data you collected. Scaling laws determines how much optimal data is required to train a model of a particular size.
If you are interested in learning more about how the latest Llama 3 large language model (LLM)was built by the developer and team at Meta in simple terms. You are sure to enjoy this quick overview guide which includes a video kindly created by Tunadorable on how to build Llama 3 from scratch in code. Now that we know what we want our LLM to do, we need to gather the data we’ll use to train it. There are several types of data we can use to train an LLM, including text corpora and parallel corpora. We can find this data by scraping websites, social media, or customer support forums. Once we have the data, we’ll need to preprocess it by cleaning, tokenizing, and normalizing it.
Transfer learning is a unique technique that allows a pre-trained model to apply its knowledge to a new task. It is instrumental when you can’t curate sufficient datasets to fine-tune a model. When performing transfer learning, ML engineers freeze the model’s existing layers and append new trainable ones to the top. ChatGPT has successfully captured the public’s attention with its wide-ranging language capability. Shortly after its launch, the AI chatbot performs exceptionally well in numerous linguistic tasks, including writing articles, poems, codes, and lyrics. Built upon the Generative Pre-training Transformer (GPT) architecture, ChatGPT provides a glimpse of what large language models (LLMs) are capable of, particularly when repurposed for industry use cases.
At the bottom of these scaling laws lies a crucial insight – the symbiotic relationship between the number of tokens in the training data and the parameters in the model. This guide describes the core steps of the process – the definition of aims and objectives, data collection, training, model tuning, and optimization. The benefits of developing a specific LLM include more precision and specialization, better data protection and security, reduced dependence on third-party services, and even cost efficiency.
Although this step is optional, you’ll likely find generating synthetic data more accessible than creating your own set of LLM test cases/evaluation dataset. If you’re interested in learning more about synthetic data generation, here is an article you should definitely read. When fine-tuning, doing it from scratch with a good pipeline is probably the best option to update proprietary or domain-specific LLMs. However, removing or updating existing LLMs is an active area of research, sometimes referred to as machine unlearning or concept erasure. If you have foundational LLMs trained on large amounts of raw internet data, some of the information in there is likely to have grown stale.
Encoder-only, decoder-only, and encoder-decoder combined architectures are common choices for LLMs. Transformers offer flexibility in design, such as incorporating residual connections, layer normalization, and activation functions like Glu, GELU, or ReLU. Retrieval-augmented generation (RAG) is a method that combines the strength of pre-trained model and information retrieval systems. This approach uses embeddings to enable language models to perform context-specific tasks such as question answering. Embeddings are numerical representations of textual data, allowing the latter to be programmatically queried and retrieved. ClimateBERT is a transformer-based language model trained with millions of climate-related domain specific data.
A strong background here allows you to comprehend how models learn and make predictions from different kinds and volumes of data. Tokenization — Language models (i.e. neural networks) do not “understand” text; they can only work with numbers. Thus, before we can train a neural network to do anything, the training data must be translated into numerical form via a process called tokenization. Researchers typically use existing hyperparameters, such as those from GPT-3, as a starting point. Fine-tuning on a smaller scale and interpolating hyperparameters is a practical approach to finding optimal settings.
We are going to use the training DataLoader which we’ve created in step 3. As the total training dataset number is 1 million, I would highly recommend to train our model on a GPU device. After each epoch, we are going to save the model weights along with the optimizer state so that it would be easier to resume training from the point before it building llm from scratch stopped rather than resume from the start. Consequently, the transformer has emerged as the current state-of-the-art neural network architecture and has been incorporated into leading LLMs since its introduction in 2017. After training and fine-tuning your LLM, it’s crucial to test whether it performs as expected for its intended use case.
Training large language models comes with significant computational costs. Techniques like mixed precision training, 3D parallelism (including pipeline parallelism, model parallelism, and data parallelism), and zero redundancy optimizer can be employed to speed up training. Training stability can be achieved through checkpointing, weight decay, and gradient clipping. Determining hyperparameters like batch size, learning rate, optimizer, and dropout is crucial for optimal training.
By automating repetitive tasks and improving efficiency, organizations can reduce operational costs and allocate resources more strategically. Businesses are witnessing a remarkable transformation, and at the forefront of this transformation are Large Language Models (LLMs) and their counterparts Chat GPT in machine learning. As organizations embrace AI technologies, they are uncovering a multitude of compelling reasons to integrate LLMs into their operations. The exorbitant cost of setting up and maintaining the infrastructure needed for LLM training poses a significant barrier.
Preprocessing entails “cleaning” it — removing unnecessary information such as special characters, punctuation marks, and symbols not relevant to the language modeling task. With all of this in mind, you’re probably realizing that the idea of building your very own LLM would be purely for academic value. Still, it’s worth taxing your brain by envisioning how you’d approach this project. So if you’re wondering what it would be like to strike out and create a base model all your own, read on. But only a small minority of companies — 10% or less — will do this, he says.
5 ways to deploy your own large language model – CIO
5 ways to deploy your own large language model.
Posted: Thu, 16 Nov 2023 08:00:00 GMT [source]
The resulting new query, key, and value embedding vector has the shape of (seq_len, d_model). The weight parameters will be initialized randomly by the model and later on, will be updated as model starts training. Because these are learnable parameters which are needed for query, key, and value embedding vectors to give better representation.
Roughly, they recommend 20 tokens per model parameter (i.e. 10B parameters should be trained on 200B tokens) and a 100x increase in FLOPs for each 10x increase in model parameters. Adi Andrei explained that LLMs are massive neural networks with billions to hundreds of billions of parameters trained on vast amounts of text data. Their unique ability lies in deciphering the contextual relationships between language elements, such as words and phrases. For instance, understanding the multiple meanings of a word like “bank” in a sentence poses a challenge that LLMs are poised to conquer.
These nodes require the selection of model ID, the setting of the maximum number of tokens to generate in the response, and the model temperature. In the “Advanced settings”, it’s possible to fine-tune hyperparameters, such as how many chat completion choices to generate for each input message, and alternative sampling strategies. Choosing the build option means you’re going to need a team of AI experts who are able to understand and implement the latest generative AI research papers. It’s also essential that your company has sufficient computational budget and resources to train and deploy the LLM on GPUs and vector databases.
-

 Health10 months ago
Health10 months agoDiscover ://vital-mag.net Blog: Expert Tips for Total Wellness
-
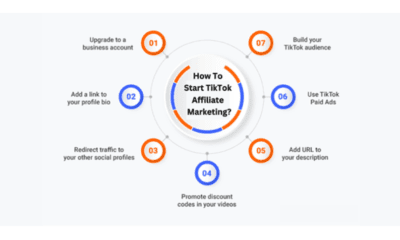
 Business11 months ago
Business11 months agoTikTok Affiliate Marketing | A Complete Guide for Marketers and Creators |
-

 Home and Gardening11 months ago
Home and Gardening11 months agoSunset Gardens Apartments: Complete Guide
-

 Health11 months ago
Health11 months ago7 Day Juice Fast Weight Loss Results: Expectations & Strategies
-
 Life style11 months ago
Life style11 months agoWhy i stopped eyelash extensions?
-

 Business11 months ago
Business11 months agoSecret Strategies of Competent Trading Companies
-

 Business11 months ago
Business11 months agoExploring the Social Media App Banality of Life
-

 entertainment11 months ago
entertainment11 months agoSWGoH Webstore: Improving Player Experience